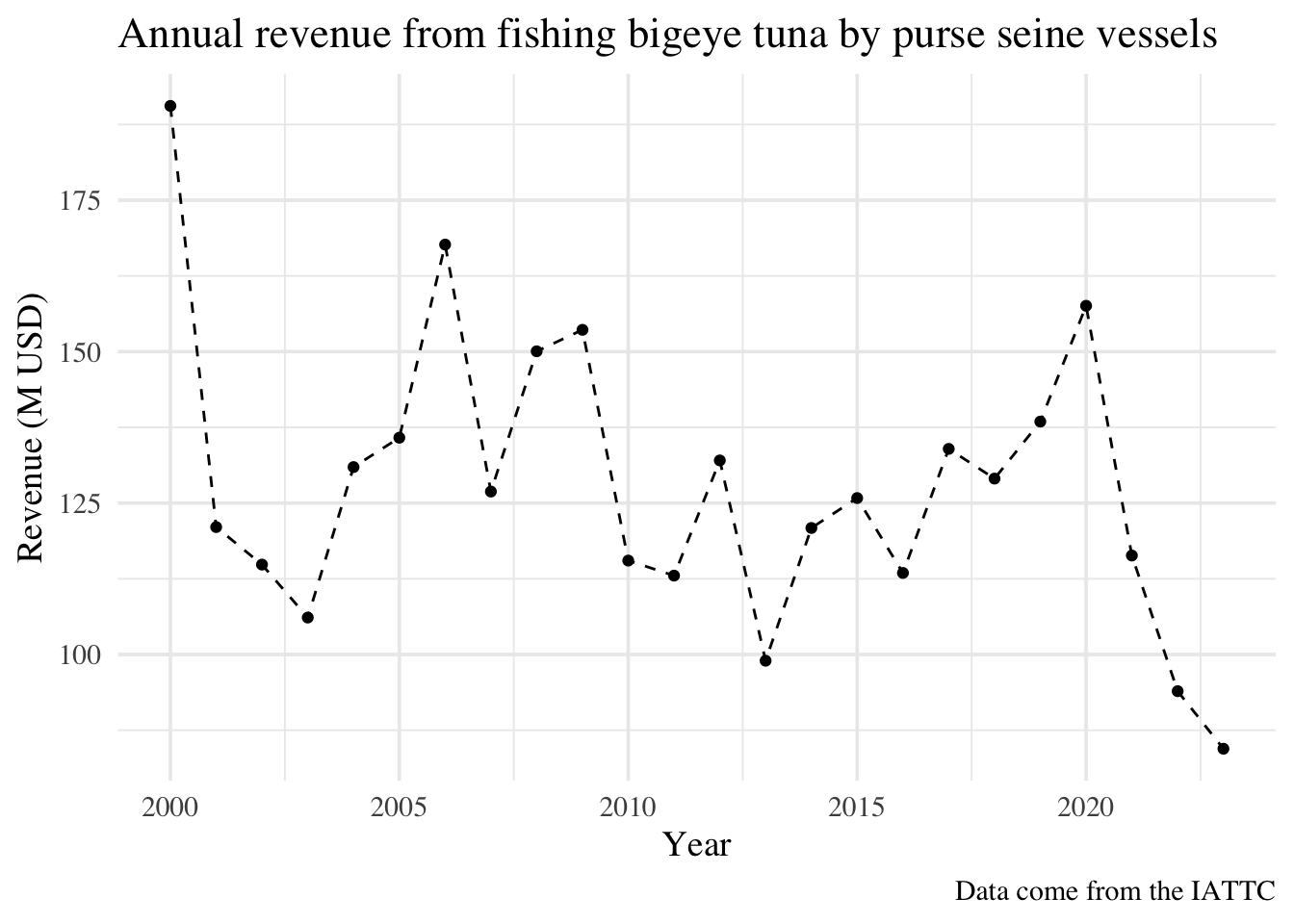
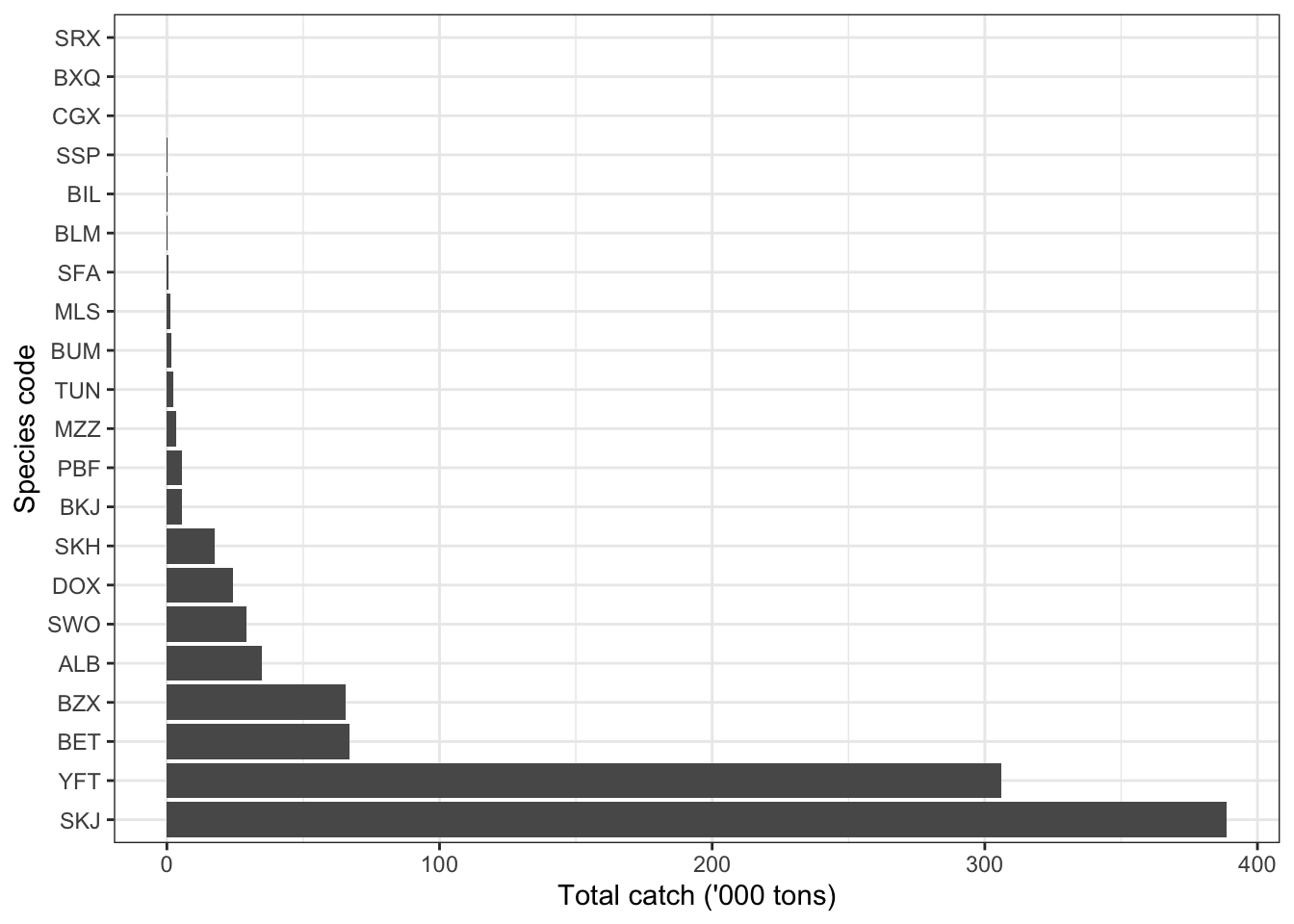
# Load packages
library(tidyverse)
library(janitor)
# Load the data
tuna_data <- read_csv("data/raw/CatchByFlagGear/CatchByFlagGear1918-2023.csv")Rows: 13595 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): BanderaFlag, ArteGear, EspeciesSpecies
dbl (2): AnoYear, t
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# Check colnames after cleaning names
colnames(tuna_data)[1] "AnoYear" "BanderaFlag" "ArteGear" "EspeciesSpecies"
[5] "t"